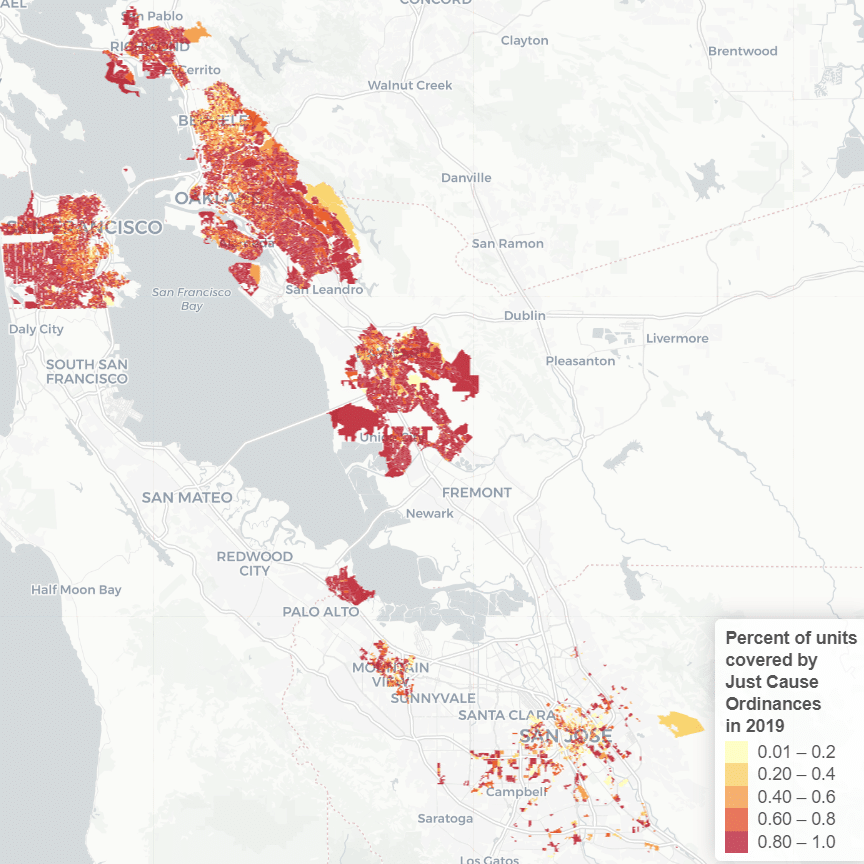
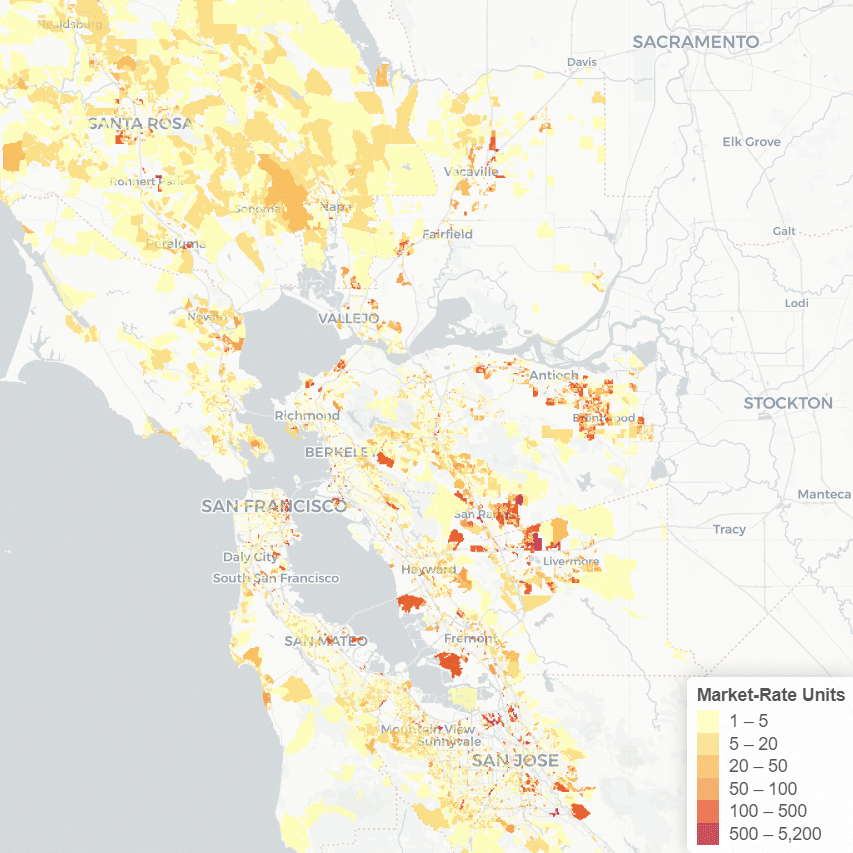
Each week from August 10 to 25, 2020, the University of California – Berkeley’s Urban Displacement Project and the University of Sydney’s Urban Housing Lab hosted its second symposium on neighborhood change funded by the Urban Studies Foundation and co-sponsored by the Berkeley Institute for Data Science. The conference brought together urban and data science researchers from universities in countries across the world including Argentina, Australia, Belgium, Hong Kong, Sweden, the U.K., and the U.S., in addition to over 180 registrants (with about 40 participating in each session). Building on the Berkeley January conference, this event brought together some of the world’s leading urban theorists with data scientists at the cutting edge of urban modeling to reflect on the state of the field and propose tools to steer change in cities.
Loretta Lees (University of Leicester) kicked off the symposium with a keynote paper “agitating” on the application of big data and machine learning techniques in gentrification studies, pointing out both issues and possibilities with these approaches. She warned about the uncomfortable commercial potential of gentrification prediction techniques: “I can’t tell you how many times I’ve been contacted by companies asking me to predict the next gentrification frontier.” With the new ease of algorithmic analysis, are we just replicating the mistakes of early gentrification scholars? Nonetheless, Lees noted that these prediction tools offer powerful foresight for fighting gentrification that have the potential for net benefit, especially if researchers design them in ways that help understand why and how gentrification takes place, not simply where or whether it is occurring. To meet this need, she challenged researchers to push beyond black box models that may offer strong predictions, but fail to reveal causal mechanisms that are important for developing effective anti-gentrification policy.

Echoing Lees’ call to step back from the exuberance of new data and models, Matthew Zook and Ate Poorthuis (University of Kentucky and KU Leuven) reflected on the efficacy of using crowdsourced geodata to examine neighborhood change, structuring their analysis into four eras of internet crowdsourcing that began in the mid-2000s, with early web mapping and geotagged social media. Despite the dazzle of big data, small data, especially from the national census, remains essential for social science research. They ended with a call to regularize and critically reflect on the use of geodata in social sciences.
With a theoretical discussion of the evolving definitions and drivers of gentrification, Derek Hyra (American University), working with colleagues Mindy Fullilove, Dominic Moulden, and Katharine Silva, linked these micro neighborhood changes to macro financial forces connected to the Great Recession. He identified a “fifth wave” of gentrification in the 2010s associated with housing financialization and speculation, particularly in the rental market. This framework provided participants an opportunity to reflect on how data availability has actually shaped understandings of gentrification and urbanism more broadly.
The conversation then shifted to prediction, as Michael Batty (University College London) considered how networks of connections between actors might predict urban development patterns. This is similar, he noted, to the way neural networks in machine learning converge on predictions. Neural network techniques, therefore, might be used to identify common factors that steer development patterns across numerous cities through an analytic process that works similarly to systems of compromise between on-the-ground stakeholders.
Another set of researchers presented innovations in methods and definitions of neighborhood change. Daniele Quercia (King’s College London) described a new way to operationalize the relationship between urban cultural capital and economic capital by comparing tag data from geolocated Flickr images to housing prices, finding that neighborhoods in London and New York that have high cultural capital but low economic capital have been susceptible to gentrification. Also re-examining gentrification were Somwrita Sarkar and her colleagues Rashi Shrivastava and Nicole Gurran (University of Sydney), who investigated the tension between displacement, in which low-income residents are forced out of gentrifying neighborhoods, and “gentrification in place,” whereby low-income residents may coexist alongside higher-income newcomers. They used income mobility data to tease apart voluntary and involuntary household movement, providing evidence of low-income exclusion over time. Ricardo Pasquini (Universidad Torcuato di Tella), working with colleagues Karen Chapple and Emmanuel Lopez (University of California, Berkeley) and Maria Emilia Persico (Universidad Torcuato di Tella), investigated how to improve predictions of gentrification by augmenting conventional census data with spatial analysis of geotagged tweets. They found that Twitter data identified pre-gentrifying neighborhoods that were not revealed by census data, and allowed for analysis across geographies lacking comparable census data.
Others innovated new approaches to measuring residential segregation. Alfredo Morales (Massachusetts Institute of Technology) investigated urban segregation by using network models to describe social media interactions between residents across multiple urban areas, revealing social fragmentation that mirrored residential segregation in physical space. Yang Xu (Hong Kong Polytechnic University) presented an approach for measuring urban segregation based on a combination of human mobility, social network, and socioeconomic data. This method allowed his team to better represent time-varying dynamics in urban segregation, such as how people move and interact throughout the course of a workday rather than focusing exclusively on residential location.
A final set of presentations examined the use of big data and machine learning to spur urban change. Ray Wyatt (University of Melbourne) presented an app, called ‘Planticipate,’ which uses machine learning to predict community members’ attitudes to neighbourhood planning proposals based on demographic characteristics and training to real-world scenarios. Chris Pettit (University of New South Wales) demonstrated tools that he and his team at the City Futures Research Centre have developed to rapidly analyze the implications of different development and regulatory scenarios for property values, including the influences of short-term housing such as AirBNB rentals. Their tools draw heavily on open-source machine learning techniques to efficiently estimate property value uplift based on parcel-level data and hypothetical development plans input through a map interface, with policymakers able to use results to guide development policies such as tax increment financing.
Hendrik Walter and his colleagues Phil Hubbard and Jonathan Reades (King’s College London) examined the implications of a recent policy in London to allow conversion of office space to residential units in order to increase housing supply in this city with a highly constrained market. They found that resulting units often had “micro” floor plans and yet were some of the most expensive in London per floor area, so they may exacerbate housing inequities.
Finally, in the same vein as work on gentrification prediction presented at our January conference, Alissa Graff (University of Michigan) presented her work predicting neighborhood change using machine learning in the city of Detroit. She argued that policymakers might use such predictions to help put safety mechanisms in place against gentrification, but cautioned that they might adversely help maintain an inequitable status quo. Likewise, Tom Benson and his colleagues Arianna Salazar Miranda, Fabio Duarte, and Carlo Ratti (all from Massachusetts Institute of Technology), working with Ann Legeby (KTH Royal Institute of Technology in Stockholm), shared the methods they have been developing toward an “early warning system” that can detect neighborhood-scale gentrification in real time in order to guide forward-looking remediation. Their system uses clustering and classification techniques adapted for time series analysis to predict different types and degrees of gentrification based on web-scraped real estate data.
Altogether, almost 60 researchers presented at the January and August conferences. What is the state of the field? The use of big data and machine learning to measure and predict neighborhood change has transformed our understanding of where and whether change is occurring. But as Lees, Zook, and Poorthuis point out, we will need to forge better connections with critical social science, qualitative researchers, and traditional data sources in order to gain more insight into the how and why. As we begin to translate research findings into policy implications, we will need to design ethical safeguards that ensure that these new tools are not simply exploited for profit, but used to communicate and engage stakeholders to help shape more equitable change.