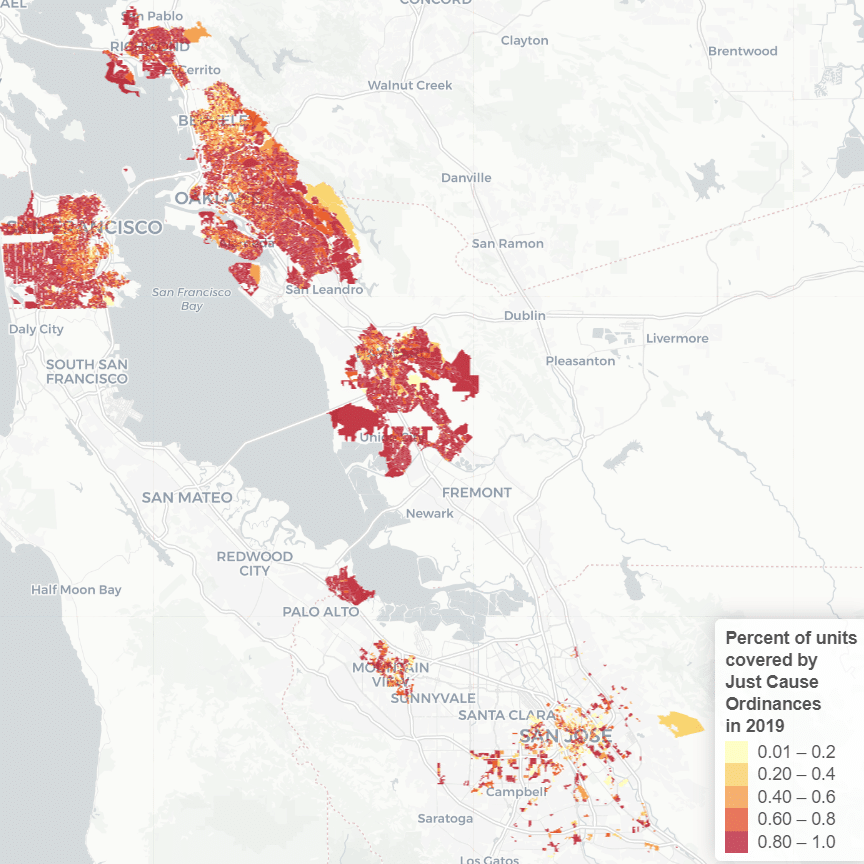
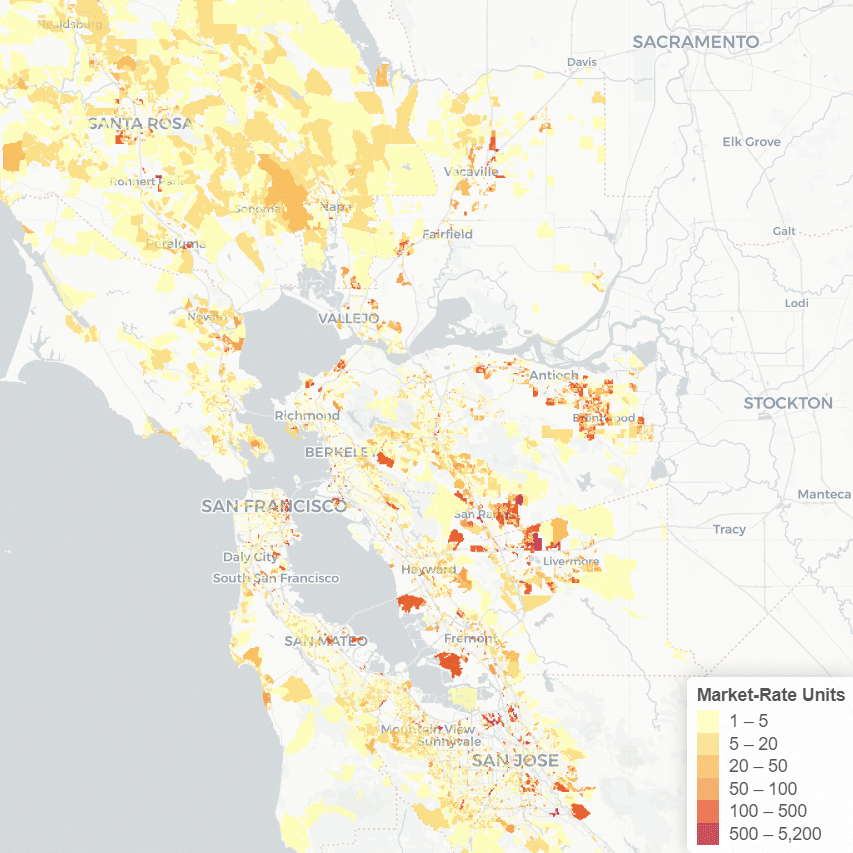
On January 9th and 10th, UC Berkeley’s Urban Displacement Project and the University of Sydney’s Urban Housing Lab hosted a symposium on neighborhood change funded by the Urban Studies Foundation and hosted by the Berkeley Institute for Data Science. The conference brought together urban researchers from universities across the United States as well as Spain, Australia, England, Argentina, Germany, and Singapore, who engaged in a lively conversation with Bay Area planners and housing advocates. The research projects discussed over the two days use machine learning and big data in innovative ways to explore, map and quantify urban change in some of the world’s most dynamic cities.

Rachel Weber (University of Illinois-Chicago) kicked off the symposium with the idea of the spatial imaginary. We can’t predict the future, so it must be imagined. What will real estate demand look like? How and where will gentrification and displacement occur? The conference papers demonstrate how harnessing the most powerful computer technology available can allow us to model how neighborhoods and even entire cities will change. In some cases, Weber argues, predictions become self-fulfilling prophecies. But we acknowledge that the power of our predictions actually lie in their ability to communicate and engage stakeholders.

Big data offers new ways to understand urban activity, which are overturning our traditional conceptions of how neighborhoods change and even simply function. Conference speakers used a variety of GPS, image, social media and acoustic data to describe change. For example, Wenfei Xu (Columbia University) calculates exposure probabilities to racial and ethnic diversity using high density mobile phone application GPS data, with the unexpected finding that exposure is highest in semi-public spaces such as big-box stores. When Xiaojiang Li (Temple University) analyzes temporal change in street tree canopies using computer vision algorithms with Google Street View data, he does not find a relationship with race and ethnicity. Using Open Street Map, Nick Bristow (University of Westminster) takes us to the level of the individual parcel, freeing density measurements from land title boundaries in order to analyze the impact of density ratios on urban form.
Two papers overlay geotagged Twitter data onto conventional census geographies to show that the spatial and temporal granularity of social media data can supplement our understanding of where gentrification is occurring. Ate Poorthuis (Singapore University of Technology and Design), Taylor Shelton (Mississippi State), and Matthew Zook (University of Kentucky) contrast visitor with resident demographic profiles to show shifts in relational connections of people to gentrifying places over time, while Karen Chapple and Eva Phillips (University of California, Berkeley) use geotagged tweets to identify areas at risk for gentrification. Finally, Allie Martin (Indiana University-Bloomington) listens to passive acoustic recordings to identify neighborhood sonic markers including displacement of go-go music and increased tensions around sound, music, and noise in public space.
Many of the talks focused on the transformation of global cities, in particular the emergence of new super-exclusive enclaves. Using a spatio-temporal longitudinal database data on real estate transactions, Jacob Macdonald (University of Liverpool) looks at spatial spillovers and the evolution of spatial boundary extents particularly in the ultra high price neighborhoods emerging in London since 2015. Using machine learning, Joshua Yee (University College London) predicts that isolated islands of super gentrification — along with several other types of gentrification — will expand markedly in the future in London. Research by Somwrita Sarkar, Nicole Gurran, and Yuting Zhang (University of Sydney) measuring exclusion in Sydney, Australia makes it clear that we need to examine neighborhood porosity at the regional scale, given rapid suburban and exurban change. Finally, José Carpio-Pinedo (Universidad Politécnica de Madrid) and Ethan Burrell (University of California Berkeley) examine the potential of using support vector machines to predict gentrification across regions (New York and San Francisco) and time periods (the 1990s and 2000s).

But others reminded us of the challenges of mapping our constructs onto data and even just escaping the confines of our pre-existing concepts. Using linked consumer and administrative records to track displacement, Jonathan Reades, Guy Lansley, Phil Hubbard (King’s College London and University College London) and Loretta Lees (University of Leicester) describe the struggle to understand the meaning of displacement for estate residents displaced to nearby versus remote locations. Eli Knaap, Sergio Rey, and Levi Wolf (University of California Riverside) remind us of the importance of proximity by analyzing gentrification using spatial Markov chains and showing how neighborhoods transition very slowly between states as a function of their previous state and the states of the surrounding neighborhoods. Randi Heinrichs (Leuphana University) asks us to examine how conceptions of neighborhood adopted by big businesses such as Amazon and social networks such as Nextdoor are reinforcing entrenched patterns of segregation and inequality while raising concerns about anonymity and privacy. These and other papers raise troubling questions about how we overcome the modifiable areal unit problem and deal with spatial dependence given the constraints of census tracts and other administrative boundaries. Given that most neighborhoods are actually quite resistant to change, are researchers propagating false narratives by selecting extreme cases like London? But then, as one housing advocate commented, how do we overcome the cognitive dissonance that is occurring as our research finds little change, while lived experience on the ground is of the violence of gentrification?

So are big data and machine learning leading to advances in our understanding of neighborhoods? Ken Steif (University of Pennsylvania) makes a compelling argument that data science is quite appropriately shifting the focus of urban researchers from causality to prediction and generalizability, which then allow us to make more effective policies and plans. Tim Thomas, Ott Toomet, Ian Kennedy, Alex Ramiller, and Jose Hernandez (University of Washington) demonstrate the potential to highlight heretofore invisible processes by using natural language processing of court records, ecological estimations, and spatial modeling to reveal racial disparities in evictions.

The conference concluded with a group discussion of the ethical and methodological risks and limitations of machine learning and harnessing big data. With local housing officials and advocates, we also considered how research might better inform policy and advocacy efforts. And finally we asked, What are the most pressing urban, housing, and neighbourhood questions for big data and machine learning to ask? Maybe by our next conference, we’ll be working on new answers!